import numpy as np
import scipy
import scipy.signal as signal
import matplotlib.pyplot as pltIn diesem Notebook wollen wir die Reglersynthese mittels LQR (Linear Quadratischer Regler) durchführen. Seine Synthese ist der Teil der optimalen Regelung. Als erstes wollen wir kurz die dynamische Programmierung wiederholen. Die dynamische Programmierung ist sowohl für die optimale Regelung als auch für das bestärkende Lernen zentral.
m1 = 1
d1 = 0.15
c1 = 0.3
m2 = 1
d2 = 0.15
c2 = 0.3
d3 = 0.15
c3 = 0.3
A = np.array([[0., 0., 1., 0.],
[0., 0., 0., 1.],
[-(c1+c2)/m1, c2/m1, -(d1+d2)/m1, d2/m1],
[c2/m2, -(c2+c3)/m2, (d2)/m2, -(d2+d3)/m2]])
B = np.array([[0., 0.], [0., 0.], [1./m1, 0.], [0., 1/m2]])
C = np.array([[1., 0., 0., 0], [0., 1., 0., 0.]])
D = np.array([[0., 0.],[0., 0.]])sys_c = signal.StateSpace(A, B, C, D)dt = 0.1
sys_d = sys_c.to_discrete(dt)R = np.eye(2)*1
Q = np.eye(4)*1Endlicher Zeithorizont
Dynamische Programmierung für nichtlineare Systeme
Betrachten wir das zeitdiskrete System
auf ein Intervall
minimiert werden. Angenommen wir haben schon eine optimale Regelung von einem gegeben Zustand
Nach Bellman, können die optimalen Kosten zum Zeitpunkt mit
angegeben werden. Wenn als schon eine Teillösung bekannt ist, müssen wir nur eine Optimierung zum Zeitpunkt
besser ersichtlich.
Dynamische Programmierung für lineare Systeme
Gegeben sei ein lineares zeitdiskretes System
mit dem Gütefunktional
mit $ S_N , Q , R > 0 $. Wir wenden nun das Prinzip der Optimalität an und starten mit
zum Zeitpunkt
durch einsetzen der Dynamik. Weil wir keine Beschränkungen auf Aktionen
errechnet werden. Wenn nun die optimale Aktion
Ein wiederholtes Vorgehen von
Code
Hinweis
Rückwärts Rekursion
Vorwärts Rekursion
def LQR_DP(A,B,Q,R,N):
""" executes the dynamic program for the discrete time finite horizon LQR (N-steps)
returns: final controller, final value-function, controller (every-step), value-function (every-step)
"""
P = np.zeros(sys_d.A.shape)
P_array = np.zeros((N,P.shape[0],P.shape[1]))
K_array = np.zeros((N,B.shape[1],B.shape[0]))
for k in range(N-1,-1,-1):
#print(k)
P = Q+A.T@P@A-A.T@P@B@np.linalg.inv(R+B.T@P@B)@B.T@P@A
P_array[k,:,:] = P
K = np.linalg.inv(R+B.T@P@B)@B.T@P@A
K_array[k,:,:] = K
return K, P, K_array, P_arrayN = 100
K, P, K_array, P_array = LQR_DP(sys_d.A,sys_d.B,Q,R,N)
Karray([[0.525914 , 0.14589593, 1.15336293, 0.20646155],
[0.14589593, 0.525914 , 0.20646155, 1.15336293]])Unendlicher Zeithorizont
In diesem Abschnitt werden wir das Problem
unendlichem Zeithorizont besprechen.
Riccati Gleichung Herleitung (Schematisch)
Für die Herleitung der Riccati Gleichung versuchen wir den Ansatz
für die Cost-to-Go Funktion.
Die optimale Bellmangleichung mit obigem Ansatz lautet
Durch das Nullsetzen und das Ableiten nach
erhalten wir
womit sich das Regelgesetz
ergibt. Die Regelparameter können also mit
berechnet werden sobald die optimale
erhalten wir die zeitdiskrete algebraische Riccati-Gleichung (DARE)
Diese Gleichung ist wohl eine der berühmtesten Gleichungen der Regelungstheorie. Es stehen effizient Methoden zum Lösen dieser Gleichung zur Verfügung.
Code
Hinweis
- 1. Riccati Gleichung
- 2. Regler Synthese
def dlqr(A,B,Q,R):
""" solves the discrete time infinite horizon LQR problem
returns: controller, matrix of the value function, closed loop eigenvalues
"""
#first, try to solve the ricatti equation
P = np.matrix(scipy.linalg.solve_discrete_are(A, B, Q, R))
#compute the LQR gain
K = np.matrix(scipy.linalg.inv(B.T@P@B+R)@(B.T@P@A))
eigVals, eigVecs = scipy.linalg.eig(A-B@K)
return K, P, eigValsK_infinite, P_infinite, eigVals_closed = dlqr(sys_d.A,sys_d.B,Q,R)
print(P_infinite)
print(K_infinite)[[16.26397985 0.33991886 5.9558398 1.49377766]
[ 0.33991886 16.26397985 1.49377766 5.9558398 ]
[ 5.9558398 1.49377766 12.68398729 2.19092355]
[ 1.49377766 5.9558398 2.19092355 12.68398729]]
[[0.52591444 0.14589589 1.15336362 0.20646134]
[0.14589589 0.52591444 0.20646134 1.15336362]]Vergleich
P_infinite_plot = np.broadcast_to(P_infinite, (N, *P_infinite.shape)).reshape(N,4*4)
K_infinite_plot = np.broadcast_to(K_infinite, (N, *K_infinite.shape)).reshape(N,2*4)P_array_plot = P_array.reshape(N,4*4)
K_array_plot = K_array.reshape(N,2*4)plt.plot(P_infinite_plot, color='black', linestyle='--');
plt.plot([], [], 'black', linestyle='--' , label='infinite') # helper plots for legend
plt.plot(P_array_plot, color='black');
plt.plot([], [], 'black', label='finite') # helper plots for legend
plt.legend()
plt.grid()
plt.ylabel('Elements of P')
plt.xlabel('time')Text(0.5, 0, 'time')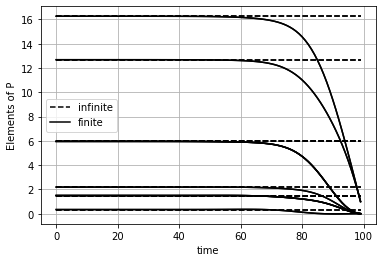
plt.plot(K_infinite_plot, color='black', linestyle='--');
plt.plot([], [], 'black', linestyle='--' , label='infinite') # helper plots for legend
plt.plot(K_array_plot, color='black');
plt.plot([], [], 'black', label='finite') # helper plots for legend
plt.legend()
plt.grid()
plt.ylabel('Elements of K')
plt.xlabel('time')Text(0.5, 0, 'time')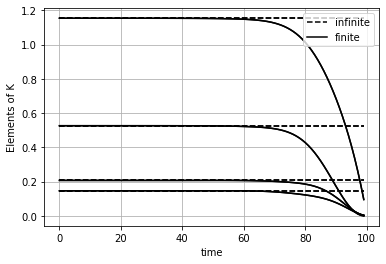
Das Problem mit endlichen Zeithorizont führt auf einen Regler
Die Regelparameter unterscheiden sich erst gegen Ende des Zeithorizonts deutlich.
Fazit
Wir haben hier die dynamische Programmierung besprochen. Für Probleme mit unendlichen Zeithorizont ist das Lösen der Riccati Gleichung die effizienteste Methode sobald ein gutes Modell vorhanden ist. Jedoch gibt es viele weitere Möglichkeiten das LQR Problem zu lösen.
Im den nächsten Blogeinträgen wollen wir Methoden aus der Künstlichen Intelligenz Forschung besprechen. Dazu führen wir aber eine etwas andere Notation ein.