Kybernetik, die Kontrolltheorie und das bestärkende Lernen
Dieser Blogeintrag soll die vielen Verbindungen und Überschneidungen der Felder Kontrolltheorie (aka Regelungstheorie) und dem bestärkenden Lernen aufzeigen. Weiters wird gezeigt, dass der Begriff Kybernetik geeignet ist, diese Felder unter einem Dach zu vereinen.
Das Maschinelle Lernen
Das bestärkende Lernen (BL) kommt aus dem Feld der Künstlichen Intelligenz (KI), insbesondere dem maschinellen Lernen (ML). Klassisch wird das maschinelle Lernen in die drei Unterklassen überwachtes Lernen, unüberwachtes Lernen und bestärkende Lernen aufgeteilt.

Das bestärkende Lernen in der KI
Beim bestärkenden Lernen interagiert ein Agent mit einer dynamischen Umgebung. Er kann dabei Aktionen an die Umgebung absetzen und so den Zustand der Umgebung verändern. Gute Aktionen in einem Zustand werden dabei mit Hilfe von Belohnungen bewertet. Der Agent versucht nun selbständig eine Strategie zu erlernen welche die Summe von Belohnungen maximiert.

Grundsätzlich lässt sich das bestärkende Lernen in verschieden mathematischen Räumen beschreiben. Die wichtigsten Unterscheidungen sind: - diskrete oder kontinuierliche Zeit - diskreter oder kontinuierlicher Zustand - deterministisches oder stochastisches System
Somit ergeben sich 8 grundsätzliche Typen von Problemformulierungen wobei aber auch zusätzliche sogenannte hybride Problemformulierungen existieren.
In der künstlichen Intelligenz wird traditional mit tabellarischen Problemen (diskrete Zeit, diskreter Zustand, stochastisches System) gestartet. Dagegen starten Ingenieure meist mit gewöhnlichen Differentialgleichungen (kontinuierliche Zeit, kontinuierlicher Zustand, deterministisches System).

Die viele Gesichter des bestärkenden Lernens
Wenn man die Anzahl aller wissenschaftliche Aufsätze in Betracht zieht, wird unmittelbar ersichtlich, dass der Großteil der Arbeit innerhalb des maschinellen Lerners stattfindet. Jedoch sei darauf hingewiesen, dass viele wissenschaftliche Felder sehr ähnliche Problemstellung studieren. Uns interessiert im Weiteren aber vor allem die Verbindung zur Kontrolltheorie.

Das Bestärkende Lernen in der Kontrolltheorie
Weniger bekannt dürfte jedoch sein, dass das bestärkende Lernen auch sehr leicht in die Kontrolltheorie einzuordnen ist. Darauf haben auch die “KI-Väter” Paul Werbos, Andrew Barto, Richard Sutton und andere hingewiesen. In ihrem 1992 erschienen Aufsatz Reinforcement learning is direct adaptive optimal control weisen Andrew Barto und Richard Sutton das bestärkende Lernen dem Teilgebiet der adaptiven Regelung zu. Werbos Beiträge in diese Richtung sind zeitlich noch früher anzusiedeln.

Die grundsätzliche Struktur des bestärkenden Lernens ist der adaptiven Regelung also sehr ähnlich. Des Weiteren gibt es je nach Algorithmus Ähnlichkeiten zu der optimalen Regelung, der modellprädiktive Regelung, der robusten Regelung, der iterativ lernenden Regelung und dem Extremwertregler.
Das bestärkende Lernen und die adaptive Regelung
Ein adaptiver Regler wird durch ein übergeordnetes System laufend verändert, um eine bessere Anpassung an ein sich veränderndes Streckenverhalten zu erreichen.

Die Bezeichnung direkte adaptive optimale Regelung wollen wir hier mit modellfreier adaptiver optimaler Regelung übersetzen. Die indirekte adaptive optimale Regelung ist dagegen modellbasiert, wobei das Modell meist aus Daten identifiziert wird.
Im Feld des maschinellen Lernens wurden in den neunziger Jahren vor allem Algorithmen entwickelt und studiert, welche ohne Systemdynamik auskommen. Die bekannteste Methode dürfte hier wohl das Q−Learning sein. Spätestens mit dem Erfolg von AlphaGo rückten aber verstärkt modellbasierte Methoden in den Fokus. Während AlphaGo und AlphaZero noch das Modell im Vorhinein benötigten kann MuZero dieses Modell selbständig lernen. Dieses Vorgehen wird innerhalb der Kontrolltheorie als indirekte adaptive optimale Regelung bezeichnet. Das Lernen von Modellen wird in der Kontrolltheorie Systemidentifikation genannt.
Die Idee dieses Vorgehens wurde bereits 1960 von dem Russen Alexander Aronovich Fel’dbaum vorgestellt und wird als Dual-Control-Theory bezeichnet. Dual, weil der Algorithmus zwei sich widersprechende Ziele verfolgen muss. Einerseits soll eine bestmögliche Regelung erreicht werden, andererseits muss das System angeregt werden um gute Daten für die Identifizierung zu erhalten. In der Regelungstechnik spricht mal von Control vs Probing/Excitation Problem. Im Feld des bestärkenden Lernens spricht man von dem Exploitation vs Exploration Dilemma.
Das bestärkende Lernen und die optimale Regelung
Das bestärkende Lernen und die optimale Regelung sind durch die dynamische Programmierung auf engste miteinander verbunden. Auch darauf weisen Andrew Barto und Richard Sutton in ihrem Buch Reinforcement Learning - An Introduction hin. Um dies zu unterstreichen werden zwei Sätze aus dem Buch hier wiedergeben.
- “We consider all ot the work in optimal control also to be, in a sense, work in reinforcement learning.”
- “[…], we must consider the solution methods of optimal control, such as dynamic programming, also to be reinforcement learning methods.”
Das bestärkende Lernen und die robuste Regelung
Eine weiter Verbindung ist mit der robusten Regelung gegeben. Ziel einer robusten Regelung ist es, einen Regler so zu entwerfen, dass eine gewisse Performance garantiert ist, ungeachtet gewisser Systemschwankungen und Störungen. Dieses Ziel wird zunehmend auf Methoden des bestärkenden Lernens übertragen.

Die robuste Regelung ist ein sehr weites und mathematisch anspruchsvolles Feld. Auf eine genau Betrachtungsweise soll hier deshalb verzichtet und auf die sehr gute Einführung Multivariable Feedback Control: Analysis and Design verwiesen werden.
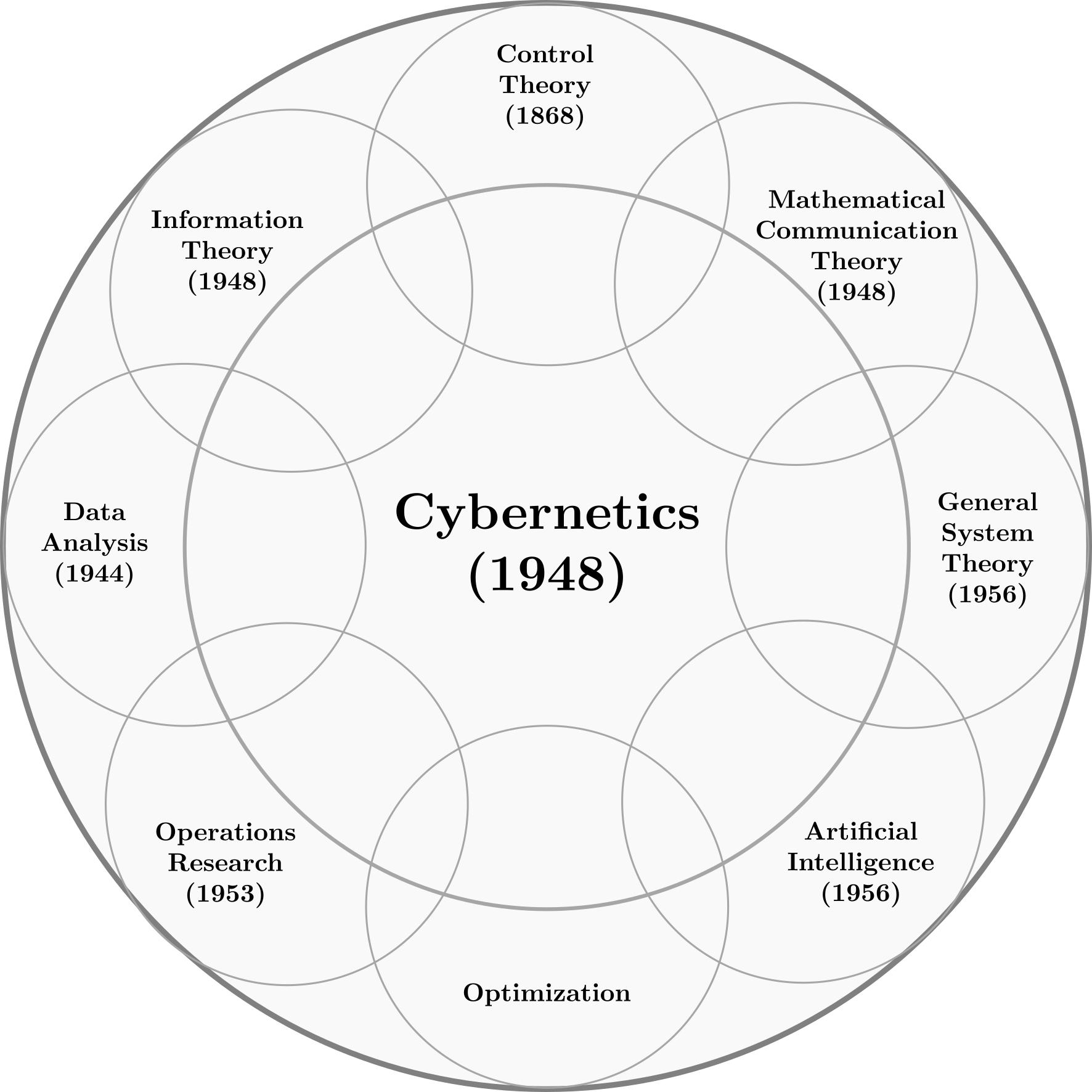
Fazit: Die Kybernetik, der richtige Begriff
Immer wieder gibt es Versuche die Kontrolltheorie vom bestärkenden Lernen abzugrenzen. Auf Twitter kann man diese Versuche gut verfolgen. Zum Beispiel hat Yann LeCun dort das bestärkende Lernen wie folgt definiert:
“RL is control without gradients and (mostly) without models” Yann LeCun
Das Problem dabei, auch in der Kontrolltheorie gibt es Methoden die ohne Gradienten und auch ohne Modelle auskommen. Andererseits verwenden viele neue KI-Methoden sehr wohl Modelle wie wir anhand von AlphaGo und dessen Nachfolger gesehen haben. Weiters gab und gibt es auch innerhalb der KI Versuche Methoden mit Gradienten zu entwickeln.
Ein weiterer Versuch Yann LeCun’s, die Kontrolltheorie vom bestärkenden Lernen zu trennen,
“Model Predictive Control is not RL. It’s optimal control.” Yann LeCun
wurde von Thomas Dietterich wie folgt beantwortet:
Model-based RL combined with short lookahead search is exactly MPC on “ML steroids” Thomas Dietterich
Die Kontrolltheorie und das bestärkende Lernen sind heute auf vielfältiger Weise miteinander verbunden. Wahrscheinlich sollten diese seit 1990er gar nicht mehr als getrennte Felder betrachtet werden, sondern als verschiedenen Methoden eines größeren gemeinsamen Feldes. Im Englischen sieht man zunehmend, dass dieser Entwicklung durch die Schreibweise Control/RL Rechnung getragen wird.
Die vielleicht beste Möglichkeit besteht in die Rückbesinnung auf den Begriff der Kybernetik. Die Kybernetik hat von Anfang an sowohl technische Maschinen, biologischen Lebewesen und ganze Gesellschaften als Ursprung einer neuen Wissenschaft gesehen und ist somit sehr inklusiv. Von Beginn an bestand die Kybernetik aus Feldern wie der Biologie, der Psychologie, der Physik, der Elektromechanik, der Operationsforschung (Operation Research), der Statistik, der Mustererkennung, der Informationstheorie und der Kontrolltheorie. Auch neuronale Netze wurden in der Kybernetik, mit der McCulloch-Pitts-Zelle, schon in den 1940er angedacht. Dagegen war die KI, Großteils auf die Logik fokussiert, ursprünglich ein Gegenprogramm der Kybernetik. John McCarthy hatte den Begriff Künstliche Intelligenz eingeführt und seine Forschungsagenda sehr an der Logik ausgerichtet. Der KI-Pionier Marvin Minsky hatte das Ziel, die Forschung an neuronalen Netzen zu beenden, was er schließlich mit dem Buch Perceptrons auch erreichte. Er hatte sich wiederholt gegen statische Methoden der KI ausgesprochen. Es ist nicht ohne Ironie, dass neuronale Netze unter dem Begriff KI, derzeit eine neue Blütezeit erleben, wo doch wichtige KI-Pioniere diesen Methoden besonders skeptisch gegenüberstanden.
Wichtige Konferenzen, welche das Feld der Kybernetik formten, waren die von 1946 bis 1953 durchgeführten Macy-Konferenzen. Zu den Themen zählten neuronale Netze, Kommunikation und Sprache, Digitale Computer, Neurophysiologie, Mustererkennung, Kindheitstraumata, Gruppendynamik und Gruppenkommunikation. Eine wichtige Konferenz, welche das Feld der Künstlichen Intelligenz formte, war die 1956 durchgeführte Dartmouth-Konferenz. Zu den Themen zählten automatische Computer, Computer & Sprache, neuronale Netzwerke, theoretische Überlegungen zum Umfang einer Rechenoperation, Selbst-Verbesserung, Abstraktionen, Zufälligkeit und Kreativität.
Wir wollen mit einem Zitat von Michael I. Jordan abschließen der sich wie folgt zu dem Begriffen Kybernetik und KI geäußert hat.
“It was John McCarthy (while a professor at Dartmouth, and soon to take a position at MIT) who coined the term AI, apparently to distinguish his budding research agenda from that of Norbert Wiener (then an older professor at MIT). Wiener had coined “cybernetics” to refer to his own vision of intelligent systems—a vision that was closely tied to operations research, statistics, pattern recognition, information theory, and control theory. McCarthy, on the other hand, emphasized the ties to logic. In an interesting reversal, it is Wiener’s intellectual agenda that has come to dominate in the current era, under the banner of McCarthy’s terminology. (This state of affairs is surely, however, only temporary; the pendulum swings more in AI than in most fields.)” Michael I. Jordan
Referenzen
- Sigurd Skogestad and Ian Postlethwaite, 2005: Mulitvarialbe Feedback Control: Analysis and Design
- Karl J. Astrom and Bjorn Wittenmark, 2008: Adaptive Control: Second Edition
- Richard S. Sutton and Andrew G.Barto, 2018: Reinforcement Learning, An Introduction, second edition
- Michael I. Jorden, 2019: Articial Intelligence—The Revolution Hasn’t Happened Yet
- https://de.wikipedia.org/wiki/Kybernetik
- https://de.wikipedia.org/wiki/Kontrolltheorie
- https://de.wikipedia.org/wiki/Künstliche_Intelligenz
- https://en.wikipedia.org/wiki/Dual_control_theory
- https://de.wikipedia.org/wiki/McCulloch-Pitts-Zelle
Historisch wichtige Personen
- https://de.wikipedia.org/wiki/Warren_McCulloch
- https://de.wikipedia.org/wiki/Heinz_von_Foerster
- https://de.wikipedia.org/wiki/Norbert_Wiener
- https://de.wikipedia.org/wiki/Hermann_Schmidt_(Kybernetiker)
- https://de.wikipedia.org/wiki/Andrew_Barto
- https://de.wikipedia.org/wiki/Richard_S._Sutton
- https://de.wikipedia.org/wiki/Michael_I._Jordan
- https://de.wikipedia.org/wiki/John_McCarthy
- https://de.wikipedia.org/wiki/Marvin_Minsky